Allen Wirfs-Brock (AWB), Waldemar Horwat (WH), Jordan Harband (JHD), Thomas Wood (TWD), Brian Terlson (BT), Michael Ficarra (MF), Adam Klein (AK), Jeff Morrison (JM), Chip Morningstar (CM), Dave Herman (DH), Yehuda Katz (YK), Leo Balter (LBR), Sebastian Markbåge (SM), Kent C. Dodds (KCD), Kevin Gibbons (KG), Tim Disney (TD), Peter Jensen (PJ), Juan Dopazo (JDO), Domenic Denicola (DD), Daniel Ehrenberg (DE), Shu-yu Guo (SYG), JF Bastien (JFB), Keith Miller (KM), Michael Saboff (MLS), Chris Hyle (CHE), Alex Russell (AR), Brendan Eich (BE), Caridy Patiño (CP), Diego Ferreiro Val (DFV), James Kyle (JK), Eric Ferraiuolo (EF), Mathias Bynens (MB), István Sebestyén (IS), Mark S. Miller (MM), Cristian Mattarei (CMI), Brad Nelson (BNN), Jafar Husain (JH)
(István Sebestyén)
IS: ...
(István was speaking remotely, over a broken audio connection, so I have no idea what he was saying. Please fill in) (Link to slides please)
IS: The slides shown have been distributed via Github and the Ecma Tc39 reflector 1 hour before the meeting. He said that 1 TC39 Standard and 1 TC39 TR will be approved (hopefully) by the Ecma General Assembly next week. He said that the JSON fast-track in JTC1 DIS ballot will end soon in December. WE have received comments from the Japanese NB, and Allen Wirfs-Brock looked at them and we took up contacts with the JApanse NB in order to eliminate the problems. According to Allen not really a big problem. Then he talked about the necessity to have a new TC39 Chair / Vice Chair selected. Until a solution is found, for a few meeting Allen Wirfs-Brock on behalf of the Secretariat will jump in. Unfortuantely, he is only willing to that that short-term.
(Discussion about new chair person)
(In response to question from DE) AWB: Chairperson should probably not have major interest in the specification and have motivation to block any particular proposal, but be technically skilled to direct the meeting. The vice-chairperson would have less of a problem with such conflict of interest.
IS: This is the ideal situation of course. In practice it is often the case that a chair person has to take position on behalf of his company on certain topics. What is important that also makes it sure when he speaks as Chair and when on behalf of his organization. Often, if he presents something on behalf of his organization he may step down as Chair and ask someone else to sit in as long as his proposal is discussed.
AWB: The dilemma is, why would someone with no interest in the specification but technically savvy with it want to come to the meetings to chair?
WH: That dilemma makes the requirements too difficult to fulfill.
BT: Don't want to do the prior ad-hoc funding arrangement. Instead, fund chair person via ECMA dues or a TC39 surcharge?
IS: ECMA's job is to provide the technical secretary, not chair person. Willing to discuss other alternatives. Ecma TC39 is too important for Ecma not to try to find a workable solution. We have to be flexible.
AWB: How do we manage a standards process with such large meetings? How do we compare to other large language committees, a new chairperson may wish to look and bring forward proposals.
AWB: No desire to continue long-term, even if funding issues were resolved. I've been doing this for 10 years, an expanded chairperson role would consume too much time. I might welcome a vice-chair position to help. But I want to move on to other things.
YK: Thanks to DE for improvements to meeting process, has assisted chair.
YK: Finding a good chair is not an emergency, in case we end up with a bad chair.
AWB: We need a collective sense of urgency here. IS: What is also important that TC39 members think about what kind of chair / vice chair (that position is also open...) they would like to see for the next period. In the past 6 years we had a chair who was not an ECMAScript expert, so really neutral, but with the current new requirements maybe a chair with some strategic guidance would be good. This is really something TC39 should think about and decide.
DFV: Salesforce willing to host Jan, but NDA issue needs to be sorted.
IS: This is the first time in my Ecma history that I am faced with an NDA issue. here Generally our meetings are Ecma meetings (hosted by somebody, but not somebody's meeting) that needs no NDA. Usually if such issues emerge, meeting participants can be requested e.g. not to walk around in the meeting bulding, but just to stay in the meeting room or the next lavatory. He offered to discuss the matter with Salesforce when he is back from the GA in December.
JM: Checklist of organisational points for meetings should be drafted.
IS: That can be done.
AWB: If salesforce are unable to resolve NDA issue are people still be willing to attend?
MM: Previously, I was threatened with physical eviction from building for not signing NDA, caved in and signed.
JH: Lawyers claim NDAs hard to enforce, recommend never signing.
AWB: Not a meeting with the host company, independent.
JM: NDA to protect host company from secret contents of building leaking, not meeting.
BT: Interpretation of NDAs often badly worded that also would cover meeting contents.
MF: Would need advance notice to run NDA past my company's lawyers.
YK: I often sign them, (to MM) do you often have this objection to NDAs?
MM: If visiting the company to meet directly with the company, it is because they're offering something, quid pro quo tradeoff. Taking on an intellectual property obligation as a part of an open standards committee meeting, it's not appropriate. If I wander around and see something secret, if the NDA was sufficianely narrowly prescribed to prevent me leaking something from I've seen wandering around, I'd be happy with that. NDA needs to be narrow for the company not to reveal secrets to me as well, to not burden me with a secret I did not want to hold.
WH: NDA at Yahoo prevented laptop or cellphone being brought into the room.
MM: ECMA is trying to be very careful about IP and patents. I'm not personally so careful outside of committee activities. It is important that we stay clear of these conflicts for ECMA in our role at meetings.
BT: No NDA was signed at Redmond.
AWB: Microsoft have sanitary spaces to hold non-NDA meetings.
JH: I could be fired for not consulting lawyers before signing an NDA on behalf of my company.
YK: We should ask for NDA allowance before meeting, if sufficient time.
CP: January would be hard, but could try for Salesforce meeting.
SYG: Mountain View Mozilla space has max of 32-34 people. There is also a v large open room, but next to kitchen, people come and go, not suitable. SF Mozilla room would take less than 30 people, previously had 40 people sign up there, not sure how many showed up. SF room was poor shape.
AK: Google SF still awaiting response for Jan.
BT: Mozilla is a fallback, should wait for Google SF to respond.
AWB: 24 hours at least to wait for response. Could do conditional - tentative Salesforce, but fallback to another. Would have to be resolved quickly. Revisit this again tomorrow.
AWB: Has anybody reviewed strawman meeting dates for rest of year? Any conflicts?
DD: Does not conflict with JSConf EU. Can't guarantee no conflict with confs in Sept/Nov.
YK: Conflict in Mar 28-29 with Emberconf.
AWB: Please bring up issues asap.
AWB: Would Mar 21-23 work?
YK: ok
March meeting changed to 21-23
DD: Jewish holidays surround Sep meeting.
AWB: Resume discussion tomorrow. Ideally cities, at least hosts to be determined.
IS has uploaded to Reflector.
WH: Not ready to approve yet. Will read overnight.
(Shu-Yu Guo)
SYG: Goal: Advance SAB to Stage 3. We have already agreed on agents and the API, and are at Stage "2.95". Since then, we revised the memory model to fix a bug from WH.
SYG: The memory model should answer questions such as, is the following optimization valid? Probably not; it would be weird if this ever printed 0.
Should we allow this optimisation?
let x = U[0];
if (x)
print(x);
To:
if (U[0])
print(U[0]);
YK: How should this code be interpreted?
(Committee: JS, or pseudocode, or imagine it's typed; whatever)
SYG: What about
while (U8[0] == 42);
===>
let c = U8[0] == 42;
while (c);
AWB: No
WH: The answer is yes.
AWB: (surprised) Why?
WH: The consensus of programming languages is that this optimization is allowed. If you were to set the answer to "no", you'd lose too many opportunities for simple optimizations needed to get good performance.
SYG: OTOH, the same thing with atomics would be disallowed.
SYG: Independent reads/independent writes in parallel threads don't have to be ordered in a consistent way as viewed by other threads. It is allowed to be acausal, and this happens on ARM and Power. Not a simple interleaving of instructions!
WH: Memory model defines which paradoxes are allowed for two reasons: - Model what the hardware is doing - Provide a model for what compiler optimizations are valid
SYG: Complicated math, but helps implementations decide what to do
SYG: Memory model could have a lot of undefined behavior, but this tries to be fully defined, to provide interoperability and security. Also need to work with WebAssembly with a common model.
MLS: Will WebAssembly use this?
JFB: Yes
SYG: Goal: Strong enough for programmers to reason
DH: Sequential consistency is already hard to use, and you need to build abstractions to make it more usable
(discussion about sequential consistency and data races)
WH: You can trivially turn any program into a sequentially consistent, data-race-free program by turning all reads and writes into atomic reads and writes. That does not make it correct!
SYG: Implementer intuition: non-atomics compiled to bare loads and stores, atomics compiled to atomic instructions or fences. For optimizations, atomics carved in stone, reads and writes stable (no rematerialization of reads, or observable changes to writes), don't remove writes. Semantically, you can reduce the size of the semantic space, but not enlarge it.
SYG: No rematerialization. Can't turn one read into multiple reads [see first example above].
WH: Note that the converse is often allowed. It's often fine to turn multiple reads done by a thread into one read.
SYG: Notions of atomicity: access atomicity (can't be interrupted--easy part), copy atomicity (when accesses are visible to other cores--ordering/timing is the hard part)
DH: Multicore processors are just distributed databases and as bad as webapps.
SYG: Memory model describes all this with a bunch of math, written in the spec, very different from the rest of the spec language. Our atomics are the same as C++ memory_consistent_atomics, or LLVM SequentiallyConsistent. Non-atomics are between non-atomics and C++ memory_order_relaxed, or between LLVM non-atomics and Unordered--a bit more strict than the total non-atomics.
WH: memory_order_relaxed is a bit stronger
SYG: We are in new territory, in terms of the strength of guarantees for non-atomics. See spec for details, or more description in the slides.
WH: The rest of the ECMAScript standard is described prescriptively. But the memory model is a filter on all possible executions and ways it could happen. In the spec mechanism, you run the program, you return all possible bit values for every read, and the memory model later retrospectively says which executions were valid. This is different from sort, where you have choices but don't mess with causality.
DH: The rest of the spec is operational semantics, and the memory model is axiomatic semantics.
AWB: Will implementers be able to read this and follow it?
SYG: The specification is a bit inscrutible. Because it's a filter on all possible executions, you can't read it and say, "I know what I'll do now".
WH: The spec is commented reasonably well with informative notes.
WH: Give me any simple example of a program transformation. By reading and following the memory model in the spec, I can give a definitive answer about whether the optimization you want to do is allowed or not.
WH: An implementation is not required to exhibit all possible executions; that's not practical or necessary.
WH: On the other hand, some concurrency is mandated by the memory model. It is not valid for an implementation to simply sequentialize all agents, running each agent one at a time until it blocks and then switching to a different agent, as that would cause deadlocks. Last week we added liveness guarantees; without those things, the atomic busy wait example earlier in the presentation wouldn't work.
SYG: Stage 3?
BT: How many implementations do we have?
BN: Four! Chrome, Firefox, WebKit and Edge.
DH: Memory models are hard, so it's OK for us to refine this in the future. But it's great that we have a starting point with a model, so we have a place to talk about which optimizations are legal. But no way to know it's perfect.
SYG: There will be bugs, and academics will write papers on our bugs for the next 10 years
DD: We will be able to write Test262 tests
WH: In prior iterations of the memory model over the last several months, I had discovered fatal counterexamples exhibiting both too much synchronization and too little. Those had required several complete rewrites of the spec to fix. I am happy with the model now.
AWB: Stage 4?
SYG: We don't have Test262 tests, that's what's missing.
JHD: How can I access an implementation?
SYG: It's on in nightly in Firefox
AK: It's in about:flags in Chrome.
AWB: If it's likely to go in soon, it'd be good for the editor to get started on the integration. Should we make it conditionally Stage 4?
AK: The editor can start on the integration work before the it really reaches Stage 4; that seems unnecessary.
AWB: Who is committing to doing Test262 tests?
SYG: I'll do them.
LH: As a starting point, the repository has tests, just not integrated yet.
DE: We will want the harness work done on implementations to get it to work
BT: Do command-line runners have a way to open agents? Chakra does. This will be useful for me to make an eshost mechanism.
AK: In d8, you can use new Worker()
LH: Firefox has a shell function for creating agents, and a shell function for sharing memory between agents.
(Leo Balter)
LBR: Bocoup has a new contract with Google, so we will work on maintanence of Test262, but this is a smaller contract, just a single day per week. We are looking for other partnerships to provide skilled work for the maintanence of Test262 to fund its development.
KG: I made a web-based Test262 runner, which we hadn't had for a while. It loads from the repository, so it should only need updates for harness changes. https://bakkot.github.io/Test262-web-runner/
(Caridy Patiño)
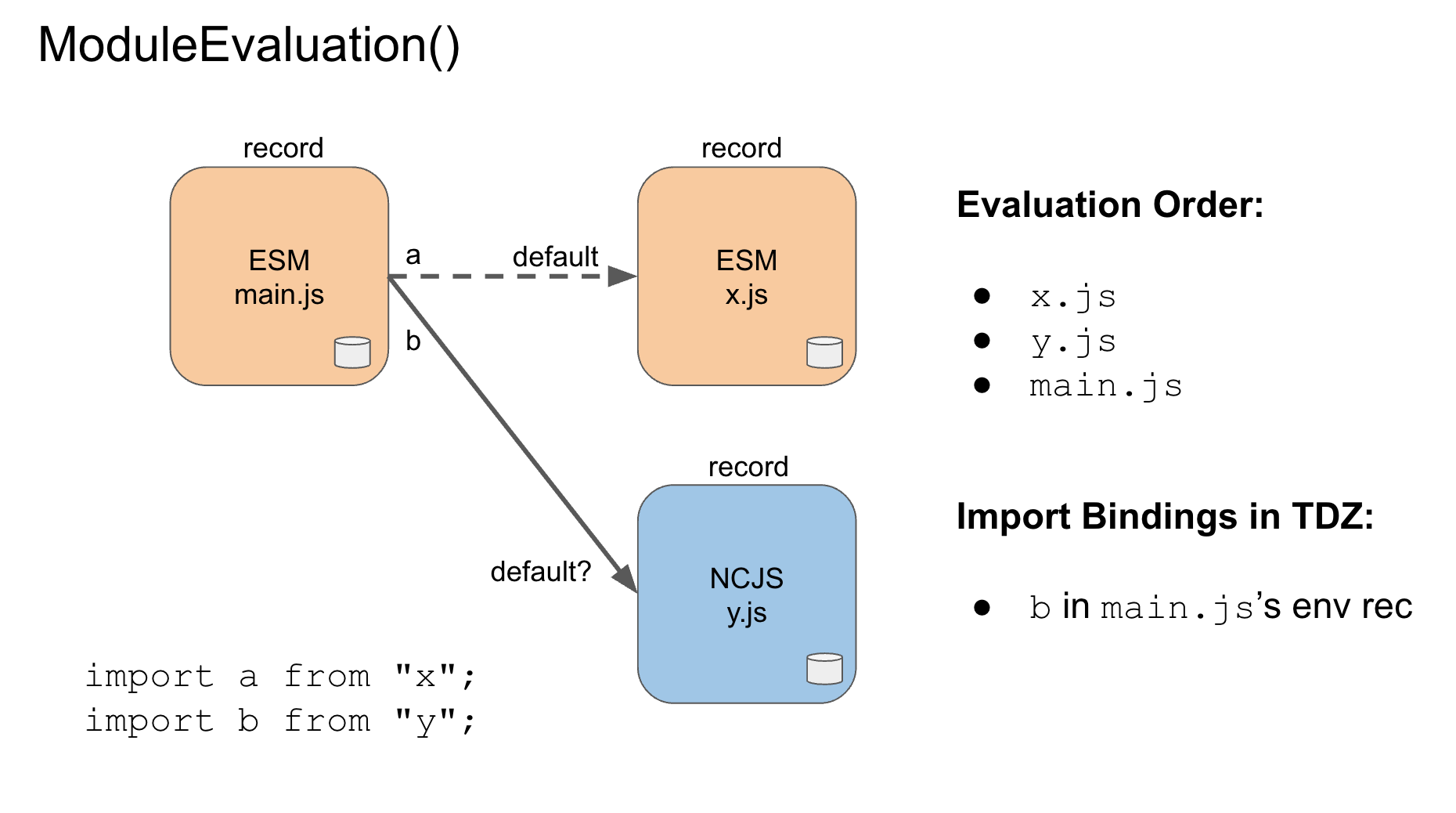
CP: Dynamic module reform: revisiting the ordering of module loading to incorporate Node.
CP: For review, ModuleDeclarationInstantiation first parses the modules, then, links the bindings. For Node, we introduce a new "pending" state for the bindings, based on the discussion from the last meeting.
AWB: For CommonJS modules, the problem is, you have to evaluate the body to find the exported names.
CP: AWB is saying, There is nothing in the spec that precludes the evaluation of the NCJS module
MM: What if we look at the imported names? It would be good to achieve certain invariants on the resulting combined system.
AWB: Node is another environment, so the body serves a different role, and we can do different things.
MM: worth examining cases where postponed evaluation is possible
AK: Don't want evaluation order to change when converting (eg. NCJS to ESM)
DH: (clarifying previous meeting consensus)
YK: node module objects are intrinsically "live", but the node representatives said no interop issue
DH: But do you snapshot the current bindings? Or read through?
AWB: Node export is values
DH: two decisions:
We don't want access to trigger side effects
AWB: what happens with commonjs modules? Evaluated only once?
JHD: If they succeed, then evaluated only once.
CP:
b go through process of determining is NCJS is still in TDZ?AWB: How does that work?
CP: walk through https://rawgit.com/caridy/proposal-dynamic-modules/master/index.html#sec-module-namespace-exotic-objects-get-p-receiver
AK: Step 7 is meaningless?
DH: Rather than spec details, let's step back to the big picture. Let's think about cycles. Could you tell me the story there?
CP: Cycles work fine with all ESM or all CJS, but the complexity is when it's mixed: Depending which you import first, you may get an error, without this proposal. Adding the "pending" state allows us to delay checking temporarily.
DH: The key design question is how we integrate them. For dynamic modules, validation of inputs being performed as late as possible--when evaluating a reference--would provide maximal interoperability, and then you can get earlier errors once you start using ESM.
AWB: A design goal of ESM was that, statically, bindings could be totally resolvable at link time (modulo TDZ, etc).
DH: That's the case in my proposal for ESM<->ESM, and for CJS, maybe a version of that could be true as well, with an extra guard.
AWB: You're suggesting that we add a different type of binding, a dynamically resolved binding. At link time, you could determine, for each import, whether it's statically resolved as an alias, or a dynamic CJS-style binding.
AK: Thinking about my implementation of modules, the spec text here is a bit incoherent--the data structures don't match up
AWB: I think that has to do with how we actually have to reflect a different kind of binding. (Question about circularity.)
DH: Previously, we had uninitialized variables, now we also have a new class of error for things that are unbound.
AWB: Probably insignificant for users.
DH: You find out later, when running your test suite, as today in CommonJS, whereas ESM finds out earlier.
YK: What would be the behavior when there is an error?
DH: ReferenceError when you actually use the variable
YK: Now it looks like a funny feature, you can import whatever names you want, and you don't get an exception unless you use it. This may be an unintentional feature.
CP: If you change your program from CJS to ESM, then you get a static error
AK: And this is a problem, making it more difficult to upgrade
CP: There are three options for the validation: 1. Don't validate anything, just check when accessing the dynamic binding, TDZ, ReferenceError 2. Whenever an ES module is about to be evaluated, if it depends on a CJS module, then go and check that the imports resolve correctly from the exported object 3. Whenever evaluating a dynamic module, check the things that it exports to and validate that there are no missing things there
DH: Option 2 has the issue with mixed circularity that you may cause something to not work, but 1 and 3 make that work. The downside of 1 is that it is too permissive, which could make evolution difficult.
AK: For some examples, 3 works out just fine and does the checking, but it still has the "fully dynamic" checking semantics if the ESM executes before the CJS.
CP: What would be the error that occurs then?
AK: ReferenceError!
CP: Which importer would be blamed by the implementation?
AK: Oh yeah, it would be a fatal not executing thing.
DH: This is a quality of implementation issue.
DE: To clarify, what's the case where you'd get the fully dynamic checking? Were we considering hoisting executing the CJS modules earlier? If it's all ESM, you never see this issue where, e.g., an exported function isn't filled in yet, as it's hoisted.
AK: A design goal here is to preserve the ordering of when the modules execute. So it might just not be filled in yet. Inherently, there are going to be some issues with circularity, but Option 3 is a good option for many of them.
DH: It's great how much progress we are making on module interop
AK: It's good that we have laid out these options, but we haven't worked out all the details and motivation for Option 3 yet. For background, it must've been more than implementation concerns that drove the current static semantics, right?
DH: Principle of least power, and ability for programmers to statically reason about their code bases, e.g., with code manipulation tools. Though soundness is not necessary for tools; seems like it's fine if we introduce this dynamic stuff which is unsound.
YK: Just because we have static linking doesn't mean we can't also have dynamic linking. ESM has already been a big benefit to tools, e.g., TS, Rollup, linters.
CP: Should my proposal be considered a PR or a staged proposal?
AWB: The spec text here is not ready yet. It should be a staged proposal.
AK: I think this is ready for Stage 1. This is an important problem, but it's a big enough change that it makes sense to think of as a proposal. It changes the model of modules significantly--goes from sound to unsound. We also need a tighter loop with Node on evaluating these options--Node currently doesn't snapshot keys, so it's even more dynamic than 1.
DH: Node has already said that snapshotting is OK, so this is a big step forwards.
DE: Are we still considering all three options?
AK: Yes
(Michael Ficarra) https://github.com/tc39/Function-prototype-toString-revision/issues/19
MF: Function.prototype.toString is supposed to maintain the source text, in the new version. Based on feedback from AWB, the current proposal normalizes all line terminators, consistent with template string literals. However, implementation feedback from Mozilla raised questions as to the cost of doing the normalization. Seems serious, should we reconsider normalization? Normalization is on 2.b-c of https://tc39.github.io/Function-prototype-toString-revision/#sec-function.prototype.tostring .
AWB: Template string literals normalize line endings so as to avoid changing the behavior of a program when run on different platforms.
WH: The same argument applies to Function.prototype.toString.
DE: At this point, the type of line break doesn't really differ all that much across platforms. It's analogous to how many spaces you include in your program--something that you do in an editor. It is just not so significant. Because of this, we should look to second-tier concerns, such as Mozilla's performance argument.
YK: Further, just returning [[SourceText]] would be the cleanest version.
MM: We shouldn't expose the platform, but editors often use native line endings. We should be consistent with template literals.
YK: There is a difference between the scenario for template literals and Function.prototype.toString(). For templates, you may want to split on \n or something, but toString is more about getting out the text from the file. Maybe you want to search for the text that you found within the file. You wouldn't want it to be messed with.
MM: The fact that entrenched tools like git will still transparently convert line endings on the same source on balance argues for normalization. Such conversions of source code should not cause a change in that code's runtime behavior. [gives example]
YK: I think returning the original source text is the right thing to do here.
MM: Raw template text data is fairly close to capturing the original source.
AK: Treating functions as a quoting mechanism is odd
MM: But people may still do it
YK: Our current notion is raw text
AWB: Even raw template text data normalizes line breaks.
AK: When would it cause a problem to not normalize?
MM: Say Git or somebody converts line endings, and then you execute the code on both platforms, and do Function.prototype.toString() and send it over the network. You would be able to observe it!
AK: But presumably you'd eval it at that point.
YK: You'd only observe that if you split the string on \n, which doesn't make any sense
MM: What does C++ do?
WH: Just checked the C++14 spec. It says that line breaks inside raw string literals evaluate to the same thing that "\n" would evaluate to in a regular string literal.
JFB: You don't want to follow C++ here because it allows identifiers to start with a non-breaking space; it's poorly thought-out.
WH: C++'s identifier conventions have nothing to do with this discussion. Plenty of unrelated warts exist in ECMAScript as well.
AWB: You can observe that the lengths are different.
AK: What about performance, and how this compares with existing implementations?
MM: Does this have significant cost?
AK: Certainly significant implementation burden. There are a lot of things we do with the source text; storing two copies would be worse than storing one. V8 stores the text that came off the wire.
AWB: Do you return a string which literally points at the input?
AK: Yes, it's just pointing at the original memory.
MLS: JSC does the same thing.
AWB: When you originally parse the thing, you can determine whether it was already normalized.
AK: OK, so now your program takes twice the memory when you check it out the wrong way in Git?
SYG: It's not that there doesn't exist a possible fast implementation. There's enough mechanism, other than toString, that requires you to directly index the original source buffer (every engine does lazy parsing), memory is too much of a concern to keep two copies. If you don't keep two copies, doing the conversion at Function.prototype.toString() time would be a pretty big expense.
AK: One of the reasons this proposal went through was to have a better specified thing which was efficiently implementable.
MM: Even if efficiency wasn't a goal for bringing it up, the lack of objections came from an understanding that there wouldn't be efficiency concerns. It's valid for people to object to the proposal who didn't object to it based on these considerations.
WH: Per MM's criteria on valid objections, I would object to this proposal if line ending normalization were removed, as it would fail to achieve its only goal. The goal of the proposal was interoperability, and it would fail to achieve that. The goal was not efficiency because platforms already had efficient implementations before this proposal.
YK: Why would it not be interoperable without line ending normalization?
MM: The observable changes that come when you change the source text. WH's concern is as valid as AK's.
YK: Engines like this because it relates to current practice
DE: This line breaking concern sounds outdated to me. All modern platforms can deal with all sorts of line endings. Just because a tool does something doesn't mean anything--should we try to make sure there are no observable changes when you write your text in an email and send it, with possible line breaks inserted?
MM: There's no way we could make that work, but we could make things be unobservable across the git line break change
YK: Currently, implementations are allowed to not change the line breaks, and this proposal makes them have to do that, so the status quo is better in that way.
AK: It's reasonable to find objections at this stage, as Stage 3 is when implementations are starting to look at this and go through with a finer eye.
MM: I want to move forward here; I would be OK with either way, though I'd prefer normalization.
AWB: What percentage of source text is already normalized? Maybe the cost here is not so big.
MLS: That would require introducing an extra scan, or a lot of extra complexity in the scanner. When we're scanning, we're looking for other things, and just ignore whitespace.
CM: Just normalize the source text as you read it.
DD: You can't do that with HTML. HTML preserves line break types. You can observe this from the DOM.
YK: Could we defer to implementers here, given that we have two valid options?
MM: All of us have valid input
DD: I am wrong; Chip was right
BT: We use source text for all sorts of things, e.g., debugging. Maintaining the mapping between the normalized and non-normalized string would be a nightmare.
AWB: Or, you could normalize way at the beginning, so you don't need the
MLS: Our parser is really performance-sensitive
KM: Recovering parser performance from async/await parsing took weeks of work
AK: A slower version of Function.prototype.toString() would be bad for users as well as developers, serving no one.
BT: I just don't see a lot of value for this. I go out of my way to avoid tools that use CRLF
SYG: My understanding was that Windows devs understand line ending difficulties, and specifically do work to counter that.
MM: I don't think that developers would do work for that
AK: Currently, they would have to, if they use Function.prototype.toString().
WH: I'd prefer to do something consistent for users rather than a premature optimization. Even if you have to make a copy of it each time.
AK: Why do you think it's not performance-critical?
WH: Why do you think it is?
DD: It's clearly used a lot in Angular
BT: How many people saw painful regressions for @@toStringTag? (All implementers raised hands.)
AK: To answer the question, I'm not likely to want to ship this with normalization.
MLS: What's the compelling use case for fast, normalized strings?
AK: Storing another copy of the normalized string is a non-starter.
WH: It's clear that efficient implementations are possible. We've already demonstrated some earlier in this discussion. Arguing the details of implementation strategies is not a productive use of this meeting.
AWB: I am flabergasted if people are writing JavaScript programs which depend on efficient Function.prototype.toString()
YK: Angular 1 calls Function.prototype.toString() functions which are dependency-injected in startup.
KD: To clarify, if you care about performance, you should turn on build-time optimizations, though not everyone does.
AK: I would recommend to the champion to discuss further with Waldemar about possible changes.
(Brendan Eich)
BE: We need a new plan not based on waiting for SIMD and/or value types, but let's do a way that doesn't depend on those and just hard-code this one to start.
BE: Let's instead start with Int64/Uint64 and then extend from there if possible, by paying attention and future-proofing as we go. In the long run we ideally want to enable libraries to create their own numeric types instead of having to hard-code each one.
BT: Could we put Decimal in through this path?
BE: Maybe, or maybe as a library. The big change here is to add a second numeric type, and then go from there.
BE: The "BBQ joint meeting" and subsequent Twitter came up with a path that allows easier incremental work: no implicit coercions, including no C-like ones. Simple dispatch with just one receiver. Literals and operators are separate proposals. For now literals and operators are hard-coded to work on these types, but the way that this is done matters and is future-proof with those separate proposals, not discussed today.
BE: ToBoolean must not throw, so this proposal hard-codes zero values instead of allowing customizable behavior for ToBoolean.
DE: Why do we need Int64/Uint64 0 to be falsy?
YK: there are languages with zeroes as truthy but it does not work for JS where we have one zero that's falsy.
BE: There are some handwaves, as decimal may have many zeroes. But, generally, numeric types ("value types") would give a canonical zero value.
BE: It's important that ++ and -- be specified as they are today as expanding to, effectively, += 1/-= 1. So we also specify a distinguished value.
MM: Does that always have to be the multiplicative identity?
BE: Eh, not sure if that comes up, but it'd meet that property.
("Consequences/examples for Int64 usage" slide)
BE: The proposal here has hard-coded literals and operator overloading, just for Int64. Literals 1L/1UL, possible to use all operators like *, etc. Operators will use ToNumeric rather than ToNumber, which may return a different Number type.
("Spec.html plan of attack and status")
DD: what is an example of when ToNumeric applies?
BE: for example, Date stuff would not, but multiplication was
DD: I see, so that you could do 5L * { valueOf() { return 4L; } }, and that would call ToNumeric first.
("Numeric Types" spec screenshot slide)
BE: unaryMinus is necessary because of -0/+0. unaryPlus is not necessary; it's always meant ToNumber, but here we change it mean ToNumeric. Separate sameValue and sameValueZero to avoid continual special-casing of +0/-0.
WH: What do you get when you divide by zero?
AWB: Are all methods mandatory?
BE: For now, all are in Int64/Uint64. Maybe in the future, these could be mapped to symbols, but not for now--all are present, and this is internal spec mechanics.
MM: because we're hard-coding, we don't need to decide on a unique NaN value?
BE: that's right, in fact there's no NaN stuff here
MM: but are you thinking in the future that, like zero and unit, they'd define a NaN value?
BE: I have not found a place in the spec that needs it, and I'd like not to if possible.
BE: In the future, maybe we could have a 'value class' syntax.
(Slide: "Future possible literal suffix support")
BE: in doing Int64/Uint64 I added early errors for out-of-range literal values; there's no good way to do that for future library-created types. I have a horrible regexp hack but it's not fun.
AWB: it seems fine to only get early errors for the built-in ones.
MF: the Uint64s can be negated?
BE: yeah sure, it's just twos-complement.
BE: No implicit conversion
WH: So you can't print them by using + to concatenate with a string?
AWB: ToString for concatenation?
BE: Yeah, sure, just not between numeric types
WH: you could also allow conversion between Int64 and Uint64; it's harmless
BE: yeah, but let's not open the door
MM: C doesn't specify that integers overflow for wrapping, just unsigned integers. I hope you specify deterministic two's complement integer overflow semantics.
WH: Yes, these should just wrap modulo 2^64.
WH: what happens when you divide by zero?
BE: I haven't specified that, but let's do throw?
WH: yeah, seems better than returning an out-of-domain value such as the Number NaN
BE: also 0L ** 0L
WH: also 3L ** -1L
WH: **, <<, >>, >>> should be heterogeneous operators. It doesn't make sense for them to require the left and right operands to have the same type.
BE: The shifts are heterogeneous. Note that they take Numbers rather than Int64/Uint64 as the right operand.
YK: Rust does some things differently, like suffixes and overflows, so we should consider all choices carefully
MM: sidestepping all the hard problems by requiring homogeneous operands is a great idea
MLS: I'd like to see Int32, and Float32, etc, it seems like a wart on the side. It would be great if we had proper types for all of these things, which would be a better way to do things for numbers that makes sense, e.g., for asm.js.
BE: I'd like to keep it limited to just these for now. Scope creep is the enemy.
WH: Historically, this is the right move; we have over the past 16 years created many int64 proposals that got expanded in scope and then collapsed under the increased weight. On the other hand, int32 is so similar to int64 that I'd like to just do it as well.
(Daniel Ehrenberg)
DE: no back compat concerns, new form added:
DE: earlier semantics was modeled after Perl (fixed-width lookbehind), but no reason not to do variable-width lookbehind
WH: Will backreferences backtrack to x a number of times if y doesn't match?
DE: will backtrack
WH: if you do forward match an assertion x, y can return to x and force x to return different captures... on lookaheads
DE: (need concrete examples to address issues)
WH: Example of what I was asking about: /(?<=(\d+))A\1/ applied to the string "01234A2345" should succeed and match the "A234" substring with capture 1 set to "234".
Current status: (see slide)
Stage 1?
WH: Concern: numbering of capture groups, they shouldn't be numbered backwards unless you also write the characters of the backwards assertion backwards, which you don't. I am only referring to how capture groups are numbered; the semantics and order in which they are filled (right-to-left) are good as is in the proposal.
BT: In other languages backward executing captures are still numbered forward. It makes it easy to find them by counting left parentheses.
DE: Can look more
BT: C# capture groups still numbered forward
WH: should be numbered forward
BT: Should, but confirm
MLS: what about negative look ahead/look behind?
=? Can do all at onceAWB: q about motivation
DE: is this feature well motivated?
Room: yes.
(Daniel Ehrenberg)
DE: Motivation: https://github.com/tc39/proposal-intl-segmenter#motivation
useful for grapheme breaking
text editor jump to next word
line breaking
sentence breaking (etc.)
V8 had a prefixed api
DE: Would like to standardize an Intl API that standardizes. Similar API: https://github.com/tc39/proposal-intl-segmenter#example
DE:
Q: Should this be a built-in module? A: Decouple from built-in modules, if this lands after built-in modules
Q: Passing in a locale for grapheme breaks? A: Pass in locale for future proofing. (per recommendation)
Q: Hyphenation? A: Might need it, but very complicated and not analogous. Likely a different API
DE: Thoughts?
DD: glad to see practical application feedback has been incorporated during design
AWB: is there a polyfill?
DE: yes
AWB: looking for the implementation feedback, multiple implementations
EF: Should we put this in Intl.js?
SM: A couple node modules can ship without the dictionaries. Shim on top of those—see if use case is still satisfied.
CM: Q about widespread need.
DE: in the C and C++ world, code always using ICU, in JS using node modules
CM: How much is exploratory design vs capturing practice?
DE: not much to it, this proposal captures the need, makes more idiomatic.
SM: Why was it added in V8 originally? That's a use case
DE: Don't know the entire history?
Terminology:
DE: V8 may violate the ES standard for NaN observable behavior, but I want to argue that it's OK
From ES2015:
SetValueInBuffer ( arrayBuffer, byteIndex, type, value [ , isLittleEndian ] ) "An implementation must always choose the same encoding for each implementation distinguishable NaN value."
Every time you get a new number, it can be scrambled at that point. Wen you put it into an ArrayBuffer, it doesn't scramble
MM: satisfies: "All operations that just move a value opaquely, without interacting with that value, none of them will enable another scramble."
DE: That was my reading
MM: This is what I was looking for, distinguishing "canonicalize" and "scramble". Dealth with information leakage, dealt with performance issues. Thank you.
DE: No
MM: All opaque conveyence of a first class value may not rescramble
JFB: Not always true. Sometimes moving a NaN changes its value on hardware.
WH: Merely moving a NaN through a floating-point register can change it.
Discussion of non-signaling vs. signaling nans
JFB: Doesn't make sense to distinguish signaling and non-signaling nans
DE: Another possibility: change language in SetValueInBuffer to rescramble
WH: (agreement)
MM: Doesn't satisfy...
(Discussion of floating registers)
WH: I don't see what the quest to nail this down to anything more than "SetValueInBuffer stores an arbitrary NaN" achieves. Arithmetic operations, maps, etc. generate arbitrary NaNs and the same concerns apply to those.
(re-ask about risks, WH and MM?)
DE: (explaining changes that eliminate information leak)
MM: Add text to SetValueInBuffer to canonical